ApFS Structure
Containers and Volumes
ApFS is structured in a single container that can contain multiple ApFS volumes. Also a container is the primary object for storing data. It needs to be > 512 Mb to contain more than one volume, > 1024Mb to contain more than 2 volumes and so on. This image shows an overview of the ApFS structure:
Each element of this structure (except for the allocation file) starts with a 32 byte block header, which contains some general information about the block. Afterwards the body of the structure is following. The following types exist:
- 0x01: Container Superblock
- 0x02: Node
- 0x05: Space manager
- 0x07: Allocation Info File
- 0x11: Unknown
- 0x0B: B-Tree
- 0x0C: Checkpoint
- 0x0D: Volume Superblock
Containers are usually exactly the same as the GUID Partition Table (GPT) entries. They have their own crash protection and disk space allocation scheme. Each container contains one or more volumes or file systems, each of which has its own namespace, that is, a set of files and directories.
ApFS does not directly support software RAID, but it can be used with Apple RAID volumes to support Striping (RAID 0), Mirroring (RAID 1), and Concatenation (JBOD).
With a 64-bit index, ApFS volumes will support up to 9 quintillion (1018) files.
The new file system uses nanoseconds to set timestamps. In HFS+ timestamps were set to the nearest second. This will reduce the number of failures in data transfer and other file operations.
ApFS has a built-in encryption system and uses AES-XTS or AES-CBC systems, depending on the device. The user can use several encryption keys to ensure data security even in the case of “physical compromise” of the medium.
This is not a complete list of the innovations that ApFS will bring. The new file system will be released for widespread use next year, and by that time, developers need to prepare to transfer the utilities to the new file system.
Partitions formatted in ApFS are not recognized by OS X 10.11 Yosemite and earlier versions of the operating system.
Block header
Each filesystem structure in ApFS starts with a block header. This header starts with a checksum for the whole block. Other informations in the header include the copy-on-write version of the block, the block id and the block type.
| pos | size | type | id |
|---|---|---|---|
| 0 | 8 | uint64 | checksum |
| 8 | 8 | uint64 | block_id |
| 16 | 8 | uint64 | version |
| 24 | 2 | uint16 | block_type |
| 26 | 2 | uint16 | flags |
| 28 | 4 | uint32 | padding |
Container Superblock
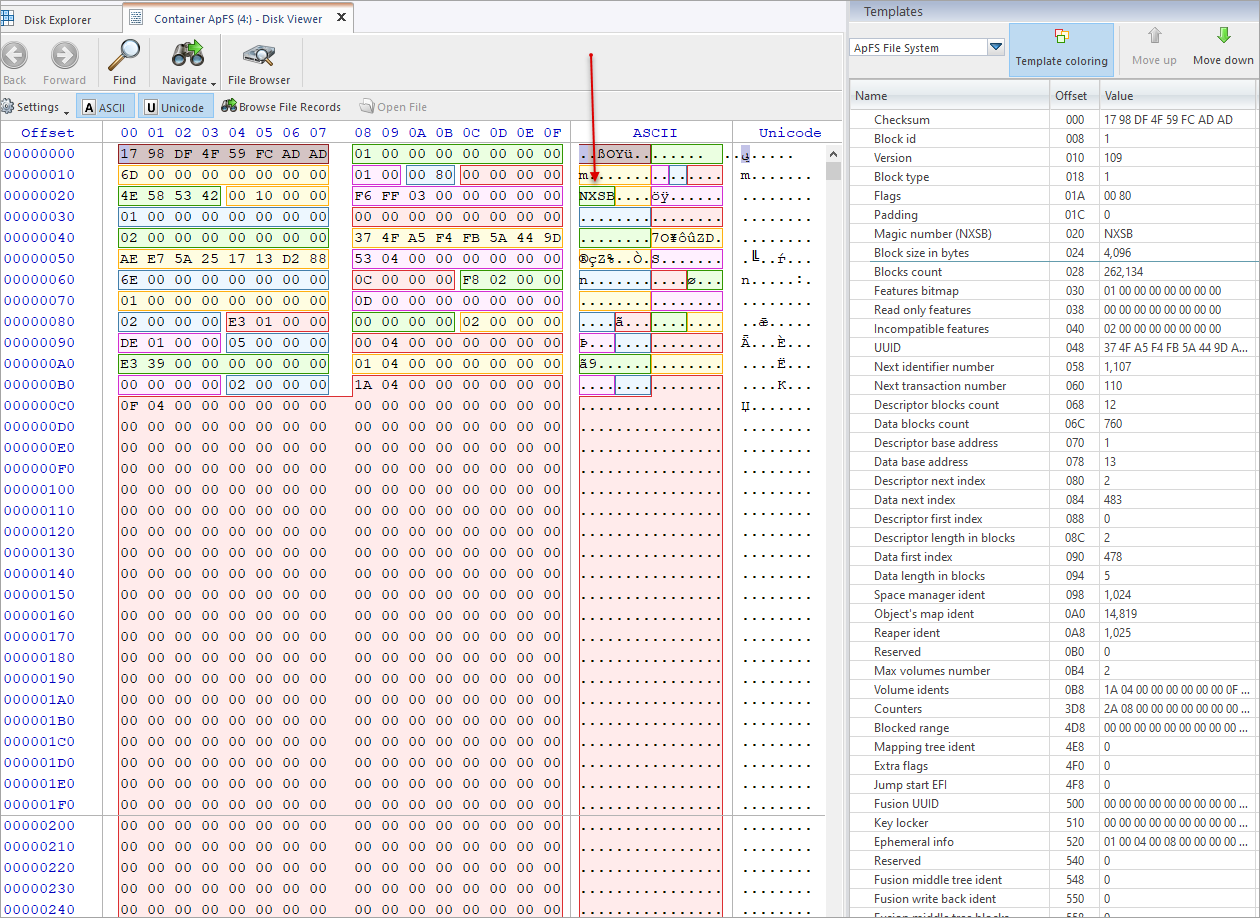
The CS (Container Superblock) is the entry point to the filesystem. Because of the structure with containers and flexible volumes, allocation needs to be handled on container level. The CS contains information on the blocksize, the number of blocks and pointers to the space manager for this task. Additionally the block IDs of all volumes are stored in the superblock. To map block IDs to block offsets a pointer to a block map B-tree is stored. This B-tree contains entries for each volume with its ID and offset. The CS is the highest level in the file system.
With type definitions of:
uint8 tApFS_Uuid;
uint64 tApFS_Ident;
uint64 tApFS_Transaction;
int64 tApFS_Address;
uint64 tApFS_BTreeKey;
and
struct tApFS_BlockRange
{
tApFS_Address First; // First block
uint64 Count; // Blocks' amount
}
struct tApFS_COH
{
uint64 CheckSum; // Control object sum
tApFS_Ident Ident; // Object identifier
tApFS_Transaction Transaction; // Object change transaction number
uint16 Type; // Object type
uint16 Flags; // Object flags
uint32 SubType; // Object subType
};
with object type enumerations:
enum eApFS_ObjectType
{
eApFS_ObjectType_01_SuperBlock = 0x0001, // Container Superblock
eApFS_ObjectType_02_BTreeRoot = 0x0002, // B-Tree: root node
eApFS_ObjectType_03_BTreeNode = 0x0003, // B-Tree: non-root node
eApFS_ObjectType_05_SpaceManager = 0x0005, // _Space Manager_
eApFS_ObjectType_06_SpaceManagerCAB = 0x0006, // _Space Manager_ segments' addresses info
eApFS_ObjectType_07_SpaceManagerCIB = 0x0007, // _Space Manager_ segments' info
eApFS_ObjectType_08_SpaceManagerBitmap = 0x0008, // Free space bitmap used by _Space Manager_
eApFS_ObjectType_09_SpaceManagerFreeQueue = 0x0009, // Free space queue used by _Space Manager_ (keys - _tApFS_09_SpaceManagerFreeQueue_Key_, values - _tApFS_09_SpaceManagerFreeQueue_Value_)
eApFS_ObjectType_0A_ExtentListTree = 0x000A, // Extents' List Tree (keys - offset beginning extent _tApFS_Address_, values - physical data location _tApFS_BlockRange_)
eApFS_ObjectType_0B_ObjectsMap = 0x000B, // Type - Objects Map; subType - Object Map record tree (keys - _tApFS_0B_ObjectsMap_Key_, values - _tApFS_0B_ObjectsMap_Value_)
eApFS_ObjectType_0C_CheckPointMap = 0x000C, // Check Point Map
eApFS_ObjectType_0D_FileSystem = 0x000D, // Volume file system
eApFS_ObjectType_0E_FileSystemTree = 0x000E, // File system tree (keys start from _tApFS_BTreeKey_, describes key type and value)
eApFS_ObjectType_0F_BlockReferenceTree = 0x000F, // Block Reference Tree (keys - _tApFS_BTreeKey_, values - _tApFS_0F_BlockReferenceTree_Value_)
eApFS_ObjectType_10_SnapshotMetaTree = 0x0010, // Snapshot Meta Tree (keys - _tApFS_BTreeKey_, values - _tApFS_10_SnapshotMetaTree_Value_)
eApFS_ObjectType_11_Reaper = 0x0011, // Reaper
eApFS_ObjectType_12_ReaperList = 0x0012, // Reaper List
eApFS_ObjectType_13_ObjectsMapSnapshot = 0x0013, // Objects Map Snapshot tree (keys - _tApFS_Transaction_, values - _tApFS_13_ObjectsMapSnapshot_Value_)
eApFS_ObjectType_14_JumpStartEFI = 0x0014, // EFI Loader
eApFS_ObjectType_15_FusionMiddleTree = 0x0015, // Fusion devices tree to track SSD-cached HDD blocks (keys - _tApFS_Address_, values - _tApFS_15_FusionMiddleTree_Value_)
eApFS_ObjectType_16_FusionWriteBack = 0x0016, // Fusion devices writeback cache status
eApFS_ObjectType_17_FusionWriteBackList = 0x0017, // Fusion devices writeback cache list
eApFS_ObjectType_18_EncryptionState = 0x0018, // Encryption
eApFS_ObjectType_19_GeneralBitmap = 0x0019, // General Bitmap
eApFS_ObjectType_1A_GeneralBitmapTree = 0x001A, // General Bitmap Tree (keys - uint64, keys - uint64)
eApFS_ObjectType_1B_GeneralBitmapBlock = 0x001B, // General Bitmap Block
eApFS_ObjectType_00_Invalid = 0x0000, // Non-valid as a type or absent subType
eApFS_ObjectType_FF_Test = 0x00FF // Reserved for testing (never stored on media)
eApFS_ObjectType_FF_Test = 0x00FF // Reserved for testing (never stored on media)
};
where:
enum eApFS_ObjectFlag
{
eApFS_ObjectFlag_Virtual = 0x0000, // Virtual object
eApFS_ObjectFlag_Ephemeral = 0x8000, // Ephemeral object
eApFS_ObjectFlag_Physical = 0x4000, // Physical object
eApFS_ObjectFlag_NoHeader = 0x2000, // Object with no _tApFS_ContainerObjectHeader_ header (for example, a Space Manager bitmap)
eApFS_ObjectFlag_Encrypted = 0x1000, // Encrypted object
eApFS_ObjectFlag_NonPersistent = 0x0800, // Object with this flag is never saved on the media
eApFS_ObjectFlag_StorageTypeMask = 0xC000, // Bitmask for accessing object category flags
eApFS_ObjectFlag_ValidMask = 0xF800 // Valid flag bitmask
};
struct tApFS_0B_ObjectsMap_Key
{
tApFS_Ident ObjectIdent; // Object Identifier
tApFS_Transaction Transaction; // Transaction number
};
struct tApFS_0B_ObjectsMap_Value
{
uint32 Flags; // Flags
uint32 Size; // Object size in bytes (a multiple of the container block size)
tApFS_Address Address; // Object address
};
struct tApFS_09_SpaceManagerFreeQueue_Key
{
tApFS_Transaction sfqk_xid;
tApFS_Address sfqk_paddr;
};
struct tApFS_09_SpaceManagerFreeQueue_Value
{
uint64 sfq_count;
tApFS_Ident sfq_tree_oid;
tApFS_Transaction sfq_oldest_xid;
uint16 sfq_tree_node_limit;
uint16 sfq_pad16;
uint32 sfq_pad32;
uint64 sfq_reserved;
};
struct tApFS_10_SnapshotMetaTree_Value
{
tApFS_Ident ExtentRefIdent; // Identifier of the B-tree physical object that stores the extent information
tApFS_Ident SuperBlockIdent; // Superblock identifier
uint64 CreatedTime; // Snapshot creation time (in nanoseconds from midnight 01/01/1970)
uint64 LastModifiedTime; // Snapshot last modified time (in nanoseconds from midnight 01/01/1970)
uint64 iNum;
uint32 ExtentRefTreeType; // Type of B-tree that stores extent information
uint16 NameLength; // Snapshot name length (including end of line character)
uint8 Name[]; // Snapshot name (ending with 0)
};
struct tApFS_13_ObjectsMapSnapshot_Value
{
uint32 Flags; // Snapshot flags
uint32 Padding; // Reserved (for adjustment)
tApFS_Ident Reserved; // Reserved
};
struct tApFS_15_FusionMiddleTree_Value
{
tApFS_Address fmv_lba;
uint32 fmv_length;
uint32 fmv_flags;
};
| Offset (HEX) | Type | Id | Description |
|---|---|---|---|
| 0 | tApFS_COH | Header | Container Object Header |
| 20 | uint32 | MagicNumber (NXSB) | A value that can be used to verify that we are reading an instance of CS |
| 24 | uint32 | BlockSize | Container block size (in bytes) |
| 28 | uint64 | BlocksCount | Container blocks' amount |
| 30 | uint64 | Features | Container basic features' bitmap |
| 38 | uint64 | ReadOnlyFeatures | Container basic read-only features' bitmap |
| 40 | uint64 | IncompatibleFeatures | Container basic incompatible features' bitmap |
| 48 | tApFS_Uuid | Uuid | Container's UUID |
| 58 | tApFS_Ident | NextIdent | Next identifier for new ephemeral or virtual object |
| 60 | tApFS_Transaction | NextTransaction | Next transaction number |
| 68 | uint32 | DescriptorBlocks | Amount of blocks used by descriptor |
| 6C | uint32 | DataBlocks | Amount of blocks used by data |
| 70 | tApFS_Address | DescriptorBase | Descriptor base address or physical object Id with address tree |
| 78 | int32 | DataBase | Data base address or physical object Id with address tree |
| 80 | uint32 | DescriptorNext | Next descriptor index |
| 84 | uint32 | DataNext | Next data index |
| 88 | uint32 | DescriptorIndex | Index of first valid element in descriptor segment |
| 8C | uint32 | DescriptorLength | Blocks' amount in descriptor segment used by superblock |
| 90 | uint32 | DataIndex | Index of first valid element in data segment |
| 94 | uint32 | DataLength | Blocks' amount in data segment used by superblock |
| 98 | tApFS_Ident | SpaceManagerIdent | Space Manager ephemeral object identifier |
| A0 | tApFS_Ident | ObjectsMapIdent | Physical object identifier of the container object map |
| A8 | tApFS_Ident | ReaperIdent | Reaper Ephemeral Object Identifier |
| B0 | uint32 | ReservedForTesting | |
| B4 | uint32 | MaximumVolumes | Maximum possible number of volumes per container |
| B8 | tApFS_Ident | VolumesIdents[100] | Volume array of virtual object identifiers |
| 3D8 | uint64 | Counters[32] | Array of counters storing container information |
| 4D8 | tApFS_BlockRange | BlockedOutOfRange | Physical range of blocks that cannot be used |
| 4E8 | tApFS_Ident | MappingTreeIdent | Physical object identifier of the tree used to track objects to be moved from locked storage |
| 4F0 | uint64 | OtherFlags | Other container functions' bitmap |
| 4F8 | tApFS_Address | JumpstartEFI | Physical object Id with EFI-driver data |
| 500 | tApFS_Uuid | FusionUuid | Fusion container UUID or zero for non-Fusion containers |
| 510 | tApFS_BlockRange | KeyLocker | Container Key Tag Location |
| 520 | uint64 | EphemeralInfo[4] | Fields' array used to manage ephemeral data |
| 540 | tApFS_Ident | ReservedForTesting | |
| 548 | tApFS_Ident | FusionMidleTreeIdent | Fusion devices only |
| 550 | tApFS_Ident | FusionWriteBackIdent | Fusion devices only |
| 558 | tApFS_BlockRange | FusionWriteBackBlocks | Blocks used for the Fusion write-back cache area or zero for non-Fusion devices |
More detailed View in LSoft Disk Viewer with ApFS template:
Volume Superblock
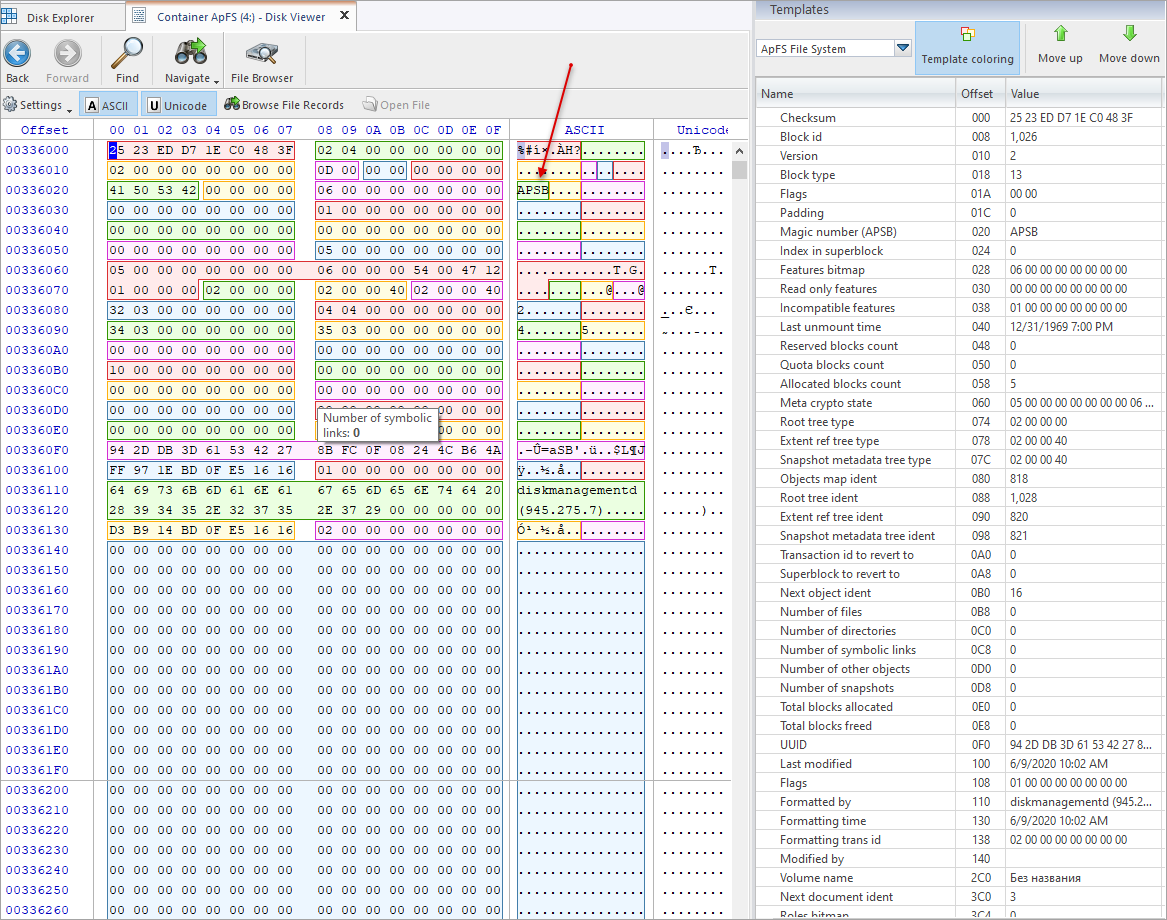
The VS (Volume Superblock) exists for each volume in the file system. It contains the name of the volume, ID and a timestamp. Similarly to the Container Superblock, it contains a pointer to a block map which maps block IDs to block offsets. Additionally a pointer to the root directory which is stored as a node is stored in the Volume Superblock.
| Offset (HEX) | Type | Id | Description |
|---|---|---|---|
| 0 | tApFS_COH | Header | Container Object Header |
| 20 | uint32 | MagicNumber (APSB) | A value that can be used to verify that we are reading an instance of VS |
| 24 | uint32 | IndexInSuperBlock | Object identifier index of this volume in the container volume array |
| 28 | uint64 | Features | Bitmap of the main features used by the volume |
| 30 | uint64 | ReadOnlyFeatures | Bitmap of the main features (Read Only) used by the volume |
| 38 | uint64 | IncompatibleFeatures | Bitmap of incompatible volume features |
| 40 | uint64 | LastUnmountTime | Time of the last unmount of the volume (in nanoseconds from midnight of 01/01/1970) |
| 48 | uint64 | ReservedBlocksCount | The number of blocks reserved to allocate the volume |
| 50 | uint64 | QuotaBlocksCount | The maximum number of blocks this volume can allocate |
| 58 | uint64 | AllocatedCount | The number of blocks currently allocated to the file system of this volume |
| 60 | uint8 | MetaCryptoState[20] | Information about the key used to encrypt metadata for this volume (wrapped_meta_crypto_state_t instance) |
| 74 | uint32 | RootTreeType | Type of the root folder tree (typically: type of (eApFS_ObjectFlag_Virtual << 16) \ eApFS_ObjectType_02_BTreeRoot, subType of eApFS_ObjectType_0E_FileSystemTree) |
| 78 | uint32 | ExtentRefTreeType | Type of extent binding tree (typically: type of (eApFS_ObjectFlag_Physical << 16) \ eApFS_ObjectType_02_BTreeRoot, subType of OBJECT_TYPE_BLOCKREF) |
| 7C | uint32 | SnapshotMetaTreeType | Snapshot metadata tree type (typically: type of (eApFS_ObjectFlag_Physical << 16) \ eApFS_ObjectType_02_BTreeRoot, subType of OBJECT_TYPE_BLOCKREF) |
| 80 | tApFS_Ident | ObjectsMapIdent | Identifier of the physical object of the volume object map |
| 88 | tApFS_Ident | RootTreeIdent | Identifier of the virtual object of the root folder tree |
| 90 | tApFS_Ident | ExtentRefTreeIdent | Identifier of the physical object of the extent link tree |
| 98 | tApFS_Ident | SnapshotMetaTreeIdent | Identifier of the snapshot metadata tree virtual object |
| A0 | tApFS_Transaction | RevertToXid | Transaction number of the snapshot to which the volume will return |
| A8 | tApFS_Ident | RevertToSuperBlock | Identifier of the physical object of the VS to which the volume will return |
| B0 | uint64 | NextObjectIdent | The next identifier to be assigned to the file system object in the volume |
| B8 | uint64 | NumberOfFiles | The number of regular files in the volume |
| C0 | uint64 | NumberOfDirectories | The number of folders in the volume |
| C8 | uint64 | NumberOfSymbolicLinks | Number of symbolic links in the volume |
| D0 | uint64 | NumberOfOtherObjects | Number of other objects in the volume (not including x0B8_NumberOfFiles, x0C0_NumberOfDirectories and x0C8_NumberOfSymbolicLinks) |
| D8 | uint64 | NumberOfSnapshots | Number of snapshots in this volume |
| E0 | uint64 | TotalBlocksAllocated | Total number of blocks allocated by this volume |
| E8 | uint64 | TotalBlocksFreed | Total number of blocks freed by this volume |
| F0 | tApFS_Uuid | Uuid | |
| 100 | uint64 | LastModifiedTime | Time of the last change of this volume (in nanoseconds from midnight 01/01/1970) |
| 108 | uint64 | Flags | |
| 110 | tApFS_0D_FSM | FormattedBy | Information about the software that created this volume |
| 140 | tApFS_0D_FSM | ModifiedBy[8] | Information about the software that changed this volume |
| 2C0 | uint8 | VolumeName[256] | UTF-8 String Zero Volume Name |
| 3C0 | uint32 | NextDocumentIdent | Next identifier of the document to be assigned (stored in the extended field APFS_0E_TYPE_DOCUMENT_ID of the document) |
| 3C4 | uint16 | Role | Volume Role Bitmap |
| 3C6 | uint16 | Reserved | |
| 3C8 | tApFS_Transaction | RootToXid | Snapshot transaction number for non-root or zero for root |
| 3D0 | tApFS_Ident | EncryptStateIdent | Current state of encryption or decryption, or zero if no encryption |
More detailed View in LSoft Disk Viewer with ApFS template:
Checkpoint
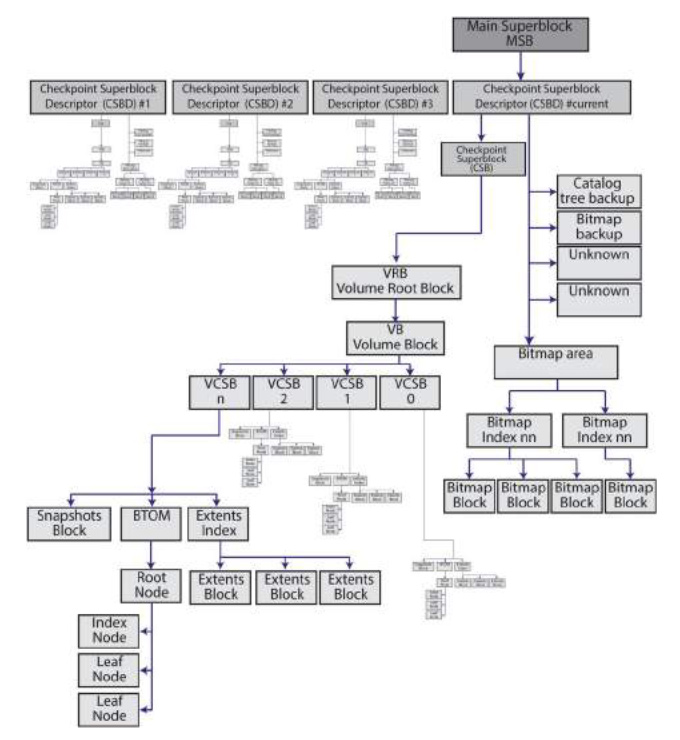
A checkpoint is a historical state of the container. Each checkpoint is initialized with CS and the current state is usually the last CS in the CS collection. The CS in the current state is the one the Main Superblock originates from. A checkpoint involves both the container and volume metadata. Restore points and snapshots are similar each other. The main difference between a checkpoint and a snapshot is the user ability to restore the file system from stored snapshots using the file system API.
Checkpoint Superblock Descriptor
This block contains information about metadata structures in ApFS and is the preceding block to the CSB (except the MSB). There is always a CSBD for each CSB. Forensically, the most important information in this block is the location of the Bitmap Structure (BMS), the former allocation file in HFS+.
Checkpoint superblock descriptor:
Bitmap Structures
Records of used and unused blocks. There is only one bitmap system that covers the whole container and is common to all volumes in the file system. From HFS+ we are familiar with the allocation file, however ApFS uses a collection of blocks to store the Bitmap Structures (BMS).
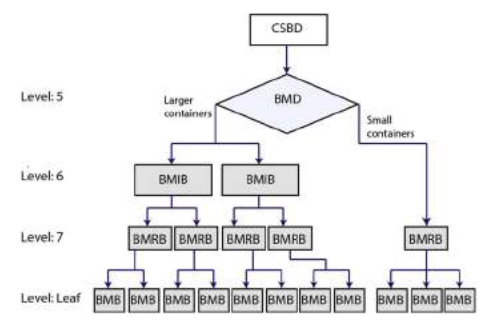
In ApFS the bitmap structures are common to all volumes in the container. Each volume has a quote of the blocks in the container but the blocks are not in dedicated areas. The BMS are referred to from the CSBD, that has information about the topmost level in the BMS, the Bitmap Descriptor (BMD). Picture below shows the basic structure of the complete BMS. The levels reflects the hierarchy where we have the BMD on the top setting the boundaries. At the bottom we have the Bitmap Blocks (BMB) that keep track of the blocks in the container. One byte in the BMB keeps track of eight blocks where each bit provides the allocation status. Each bit is the status of a single block.
Tables
Tables are used in structures such as the catalog and extent B-trees, Volume lists and the Object-ID map. 8 distinct table types have been observed so far... To fully understand ApFS it is critical to understand the structures and roles of the tables. Without interpreting the tables correctly further interpretation of the file system is almost impossible. Tables used in ApFS are small single block "databases" with slightly different purposes in the file system structures. The table type field is composed of 2 bytes located at block with offset 0x20 directly after the node header. Table types are from 0 to 7. The next 2 bytes provide the table level from 0 upwards. So far, levels 0 to 3 have been observed, but we can expect to see even larger tables' depths in large containers filled with millions of files. We have only tested volumes with up to 220,000 files and that requires four levels (0-3) in the B-Tree. A level two table will have records referring to an underlying level 1 table. Level 0 tables refer to blocks which contain file metadata often in an underlying table of level 0.
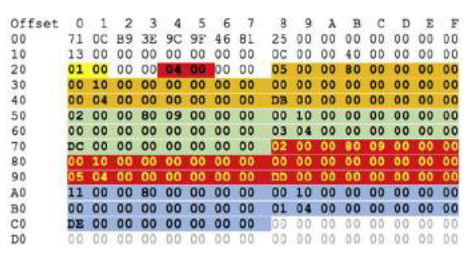
The table types are different in structure but the 24-byte table header is consistent across all table types. The following picture provides a sample table header structure:

And following table describes the meaning of the fields in this structure:
| Offset (HEX) | Field | Data type | Comments |
|---|---|---|---|
| 20 | tableType | uint16 | Possible values 0-7. This example is Table TYPE 1! |
| 22 | tableLevel | uint16 | Indicates a level of a B-Tree. This example is from the highest level in a B-Tree which has tree levels below. |
| 24 | tableRecords | uint16 | Number of records in the table. In this example there are 11 records (11 key values and 11 data values) |
| 26 | Unknown 1 | uint16 | |
| 28 | Unknown 2 | uint16 | |
| 2A | tableIndexSize | uint16 | Size of the table index area. The table key area starts right after. |
| 2C | tableKeyAreaSize | uint16 | Size of the table key area. |
| 2E | tableFreeSpaceSize | uint16 | Size of the free area. The table data area ends at offset 0x38 + tableIndexSize + tableKeyAreaSize + tableFreeSpaceSize. 0x38 + 0x80 + 0x170 + 0xd58. |
| 30 | Unknown 3 | uint16 | |
| 32 | Unknown 4 | uint16 | |
| 34 | Unknown 5 | uint16 | |
| 36 | Unknown 6 | uint16 |
A common layout of the different tables is shown here:

Not all of the elements on the picture are used in all the tables. It shows a complete block with the block/node header at the top. The remainder of the block forms the table.
Immediately after the table header is the record index. There are 2 types. One with 2 values with only offset in keys and data section each of Uint16. The other use 4 Uint16-values with offset and length for both key and data sections. The table record index has information about key and data records in the table. Another distinction between the table types are their use of footers.
Table types 1, 3, 5 and 7 use a 0x28 byte footer at the end of the block. In these tables all data offsets are relative to offset 0xFD8 and the footer contains different values specific to the table type. The other table types have no footer and all references to the data section content are relative to the end of the block. In B-trees with several layers we have table types 1, 3, 5 or7 at the top-most level as these have a footer. The footer seems to be used to store information about the complete B-Tree. One of the values in the footer is the total number of records in the whole B-Tree structure.
The 8 table types (0-7) have a lot in common and we will focus on this first. Then we provide a short description of each table type. The table definition commences at offset 0x20 in the block with table type, number of rows, size of key section and gap between key and data section. After the table setup the table row and column definitions are described from offset 0x38 in the block. The table contains a header, record definitions, key and data sections. Certain table types also have a footer. The header begins at offset 0x20 in the block and is 0x18 bytes in length. This table type header starts with a 16-bit value which represents the table type. This is then followed by two bytes representing the level in the B-Tree at which the table is used. The two subsequent bytes represent the number of rows in the table. The length of the record definition scan be found at 0x2A followed by an Uint16 which records the length of the key section. This is followed by the gap between the key and data section. The table footer is always 0x28 bytes and always occupies the end of the block. Table indices are of 4 or 8 bytes each. On 8 byte indices the two first Uint16 are the offset and length of the key record. The next two Uint16 are the offset and length of the data record in the table. Tables with 4 byte indices have two Uint16 values which is the offset to the key and data record. The data length in the two records are predefined. In tables with a footer the offset to the data record is relative to the start of the footer (0x28). And for the other table types it is relative to the end of the block.
Key offsets are relative to the start of the key section.
Most of the values regarding table header and footer are clear at least to read the type of table. Offset 0x18 in the footer (offset 0xFF in a 4 Kb block) is the number of records in the table and all underlying tables (if this is a table with level higher than 0 in offset 0x22). Offset 0x20 in the footer is the next record number in the table.
Table TYPE 0
Table TYPE 0 has been observed in the B-Tree Catalog structure (in B-Tree level) between leaf nodes and the root node. The values Unknown 3-6 appear to be the key offset and length. And the data offset and length of the next available record. If there are no free index records the offsets are set to 0xFFFF and length of 0x00.
The records in the table are four Uint16 values. The first 2 are the offset and length of value in key section and the next are the offset and value of the content in the data section.
An example of table TYPE 0 could be Catalog Node ID and named key in the key section and Object ID in data section. This table does not have a footer.
Table TYPE 1
Table TYPE 1 has a footer and the table index contains 4 16-bit values where the first 2 values are the offset to the record in the key section and the length of the record. The next 2 values provide the offset to the record in the data section and the length of this record. This table is frequently observed in both the BTCS (B-Tree Catalog Structure) and the Extents B-Tree for the top-level node. Example values are Parent ID and a key name (file/folder name in BTCS and block start number in the Extent B-Tree) in the key section and an Object ID when used as root-node in the BTCS or a block-number when used in the Extent B-Tree. Examples of this table are provided below (B-tree Catalog Root Node, BTRN) when used in the Extents B-Tree:
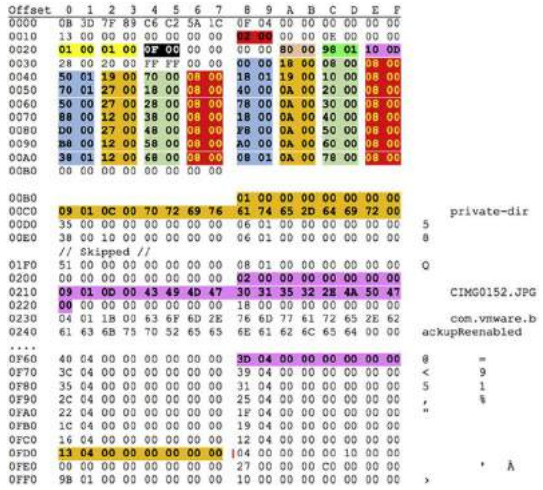
Table TYPE 2
Initially this table is identical to the previous one but has no footer. This table type is very frequently encountered in leaf nodes in the BTCS where the key section is often observed with either a Parent ID and key name or CNID and data type in the data section.
Table TYPE 3
This table is equal to the previous one. The table index is the same as table TYPE 1. Typical values depend on the structure they are used in. In the BTCS and the Extents B-Tree this table is often used as top level node in small volumes where the root node serves both as root node and leaf node. In such example of use the key record might be Parent ID. And the named key and the data record might be file metadata with large variations in size.
Other typical records could be Object ID and object type in the key record. With extent information for files in the data record. Table TYPE 3 has a footer. An example of this table used in the Extents B-tree is shown below:
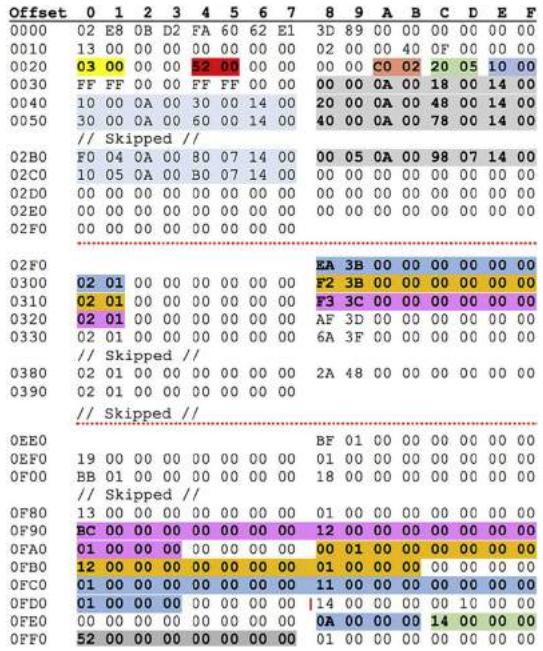
Table TYPE 4
Table TYPE 4 diverges somewhat from the previous ones. The table has no footer and the table index only has 2 values per record, the offset to the record in the key section and then 1 for the data section. The length of the content is fixed with 16 bytes in the key section and 8 bytes in the data section. Offsets in the data section are relative to the end of the block.
Table TYPE 5
Table TYPE 5 is very similar to TYPE 4. The only difference is that this type has a footer and all offsets to data are from offset- 0x28 (beginning of the footer). The records in the key section are 16 bytes and 8 bytes in the data section. This table type is mostly observed at top level nodes in the BTCS and larger containers with multilevel B-Tree‘s.
Table TYPE 6
Table TYPE 6 is very similar to TYPE 4. The table index has only the offset to content in the key and data section and not the length. The lengths are predefined. Each record is 16 bytes in both the key and data sections. There is no footer for this type of table. This type of table is often observed in the leaf nodes in the BTCS. Typical key section content includes Object ID and Volume Checkpoint Superblock ID while the data section typically records the size of the data and a block number.
Table TYPE 7
This table type is very similar to TYPE 6. The only difference is the footer that contains similar information to that described for table TYPE 1. This table type is observed in a broad range of structures and is often encountered in the top most levels of multilayer structures or in single layer structures such as the Volume declarations. An example of this type is shown below:

Tables' summary
The following table (artifacts) shows the basic properties of the different table types:
| Type | Footer | Table Indexes | Length | ||||
|---|---|---|---|---|---|---|---|
| Key Section | Data Section | ||||||
| Offset | Length | Offset | Length | Key | Data | ||
| 0 | NO | uint16 | uint16 | uint16 | uint16 | Varies | Possible |
| 1 | YES | uint16 | uint16 | uint16 | uint16 | Varies | Possible |
| 2 | NO | uint16 | uint16 | uint16 | uint16 | Varies | Possible |
| 3 | YES | uint16 | uint16 | uint16 | uint16 | Varies | Possible |
| 4 | NO | uint16 | uint16 | 16 bytes | 8 bytes | ||
| 5 | YES | uint16 | uint16 | 16 bytes | 8 bytes | ||
| 6 | NO | uint16 | uint16 | 16 bytes | 16 bytes | ||
| 7 | YES | uint16 | uint16 | 16 bytes | 16 bytes |
One of the most important blocks in the B-Tree Catalog Structure is the root node which is the highest level in the folder structure. This node utilizes search keys of variable length. One of the improved features within ApFS is Fast Directory Searching (FDS). One of the values that is tightly connected with this feature is the count of all records in the tree structure located in the table footer. In the B-Tree catalog structure the root node has only 2 options in the selection of table to use since both of these have footers. This is also according to the observations in many ApFS containers investigated. Table TYPE 3 acting as a root node is only observed in small containers with few files where the root node is also an index and leaf node. In the B-Tree Object Map only table TYPE 5 is used for the root node except in the case of very small structures where TYPE 7 may be encountered. The interpretation of the tables show that tables TYPE 0 and 2 have the same artifacts. The same is observed between tables TYPE 1 and 3. These tables appear to have a different purpose depending on which structure they are in.
Snapshots
Snapshots - readonly "snapshots" of the file system in the volume. The operating system can use snapshots for a more efficient backup procedure. Finally, Time Machine will work fine (fast). With ApFS support, for Time Machine instant images, you no longer need to save several full copies of the file to your disk - it can simply track specific changes. For example, if you are editing a PowerPoint presentation, changing a single slide using the old HFS+ means saving two copies of the file in which your new changes are recorded, and one in case you want to return. Now it can simply save the source file plus recording the differences between the source file and any updated versions, performing the same task in much less space. As with the improvements in Fusion Drive, the information takes up less space on the SSD, that is, less data is written to the disk, which ultimately will increase the life of your drive, and for such an important thing as Time Machine it is extremely important.
Of course ApFS is significantly inferior in its capabilities to the 128-bit ZFS, which is supported by Linux, FreeBSD and other free OSes but on the part of Apple this is a step in the right direction.
It is strange that the preliminary documentation does not mention the compression function that HFS+ BTW supports…
As mentioned above Apple tried to port ZFS to OS X for a long time. Later OpenZFS was implemented for OS X (O3X) and MacZFX.
Nodes
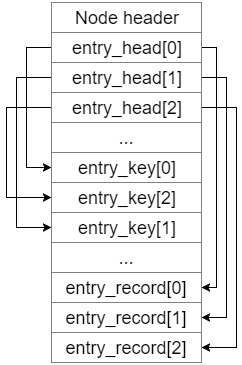
Nodes are flexible containers that are used for storing different kinds of entries. They can be part of a B-tree or exist on their own. Nodes can either contain flexible or fixed sized entries. A node starts with a list of pointers to the entry keys and entry records. This way for each entry the node contains an entry header at the beginning of the node, an entry key in the middle of the node and an entry record at the end of the node.
| pos | size | type | id |
|---|---|---|---|
| 0 | 4 | uint32 | alignment |
| 4 | 4 | uint32 | entry_count |
| 10 | 2 | uint16 | head_size |
| 16 | 8 | entry | meta_entry |
| 24 | … | entry | entries (repeat entry_count times) |
Node header structure:
| Offset | Field | Data Type | Comments |
|---|---|---|---|
| 0 | Checksum | Uint64 | Fletchers Checksum Algorithm |
| 8 | ID | Uint64 | Object-ID or Block# |
| 10 | Checkpoint ID | Uint64 | |
| 18 | Unknown | Uint16 | Possible level in B-Tree |
| 1A | Unknown | Uint16 | All observations shows value 0x4000 |
| 1C | Unknown | Uint16 | Flag? |
| 1E | Unknown | Uint16 | Often seen value 0x0b, 0x0e and 0x0f |
Space manager
The Space Manager (sometimes called spaceman) is used to manage allocated blocks in the ApFS container. Stores the number of free blocks and a pointer to the allocation info files.
| pos | size | type | id |
|---|---|---|---|
| 0 | 4 | uint32 | blocksize |
| 16 | 8 | uint64 | totalblocks |
| 40 | 8 | uint64 | freeblocks |
| 144 | 8 | uint64 | prev_allocationinfofile_block |
| 352 | 8 | uint64 | allocationinfofile_block |
Allocation Info File
The allocation info file works as a missing header for the allocation file. The allocation files length, version and the offset of the allocation file are stored here.
| pos | size | type | id |
|---|---|---|---|
| 4 | 4 | uint32 | alloc_file_length |
| 8 | 4 | uint32 | alloc_file_version |
| 24 | 4 | uint32 | total_blocks |
| 28 | 4 | uint32 | free_blocks |
| 32 | 4 | uint32 | allocationfile_block |
File and folder B-Tree
Records all files and folders in the volume. It performs the same role as the catalog file in HFS+.
Extents B-Tree
A separate B-Tree of all extents per volume. Extents are references to file content with information about where the data content starts and the length in blocks. A file with some content will have at least one extent. A fragmented file will have multiple extents. The extent B-Tree is a separate structure. In each file record extents are defined per file in the file/folder B-Tree. This separate extent structure is part of the snapshot feature.
64-bit inodes (index descriptors)
64-bit inodes significantly increase the namespace compared to 32-bit identifiers in HFS+. The ApFS 64-bit file system supports more than 9 quintillion files on each volume. That should be enough for everyone as Bill Gates said.